spark hdfs
调研目标
调研高可用分布式存储、计算框架,以适应当前和未来可期阶段的部门业务发展。
需求
- 存储为主 (如:当前simone Record目录下生成的录像文件的存储)
- 分析 (对上述大量文件进行二次分析)
- 成熟稳定 (满足日常操作需求)
市面常见方案
NFS、AFS
系统级网络通用文件系统,30年历史了,设计风格和如今有很大差异。常见用途挂载到本机,提供最容易的多用户访问方式,如NAS。
TFS
淘宝分布式文件系统,针对图片类小文件设计,前些年还打广告,github项目已废弃,官网打不开
BFS
c++分布式文件系统,百度核心业务的底层存储,为实时业务设计,而HDFS则大多用于离线批处理。
高可用,多备份, 高吞吐,raft保证一致性,负载均衡,低延时,跨机房,水平扩展,可mount到本地文件系统。部署简单,不依赖外部系统(内置raft,无虚拟机,只需要linux系统,gcc4.8+即可)

BFS部署一般包含2n+1个NameServer,3+个chunkServer.
FastDFS
一个轻量级c语言实现的分布式文件系统. 当前网盘存储大多使用该文件系统,适合中小文件(几K到几百M),没对对文件进行分块处理。非通用文件系统,只能通过API、Cli操作。不适合公网传输。 github上看并不活跃。

Amazon s3
spark默认支持的3个(hdfs、s3、local)文件系统之一.闭源收费.
moosefs
googleFS的一个C++开源实现.通用文件系统.有商业版。高可用,高容错,高一致性,在线扩容简单,负载均衡,写操作,特别是小文件效率突出。和HDFS一样,master/namenode节点随着文件增加,对内存的需求增加.1000万文件需要3G内存(和hads一样)。
GlusterFS
redhat收购的开源系统,通用文件系统,兼容hadoop文件系统。很另类的无元数据节点,采用DHT算法分布文件。高可用,多副本而弱一致性提高响应(数据传输给多个数据节点其中一个返回成功则认为成功),数据节点会定时检查副本、保持一致性。因为采用dht数据分布,扩容的时候会比其他架构的影响更大、逻辑上相邻的数据在系统里可能不在一起,而有无元数据节点,浏览、下载、删除目录会更慢,如果是小文件则更糟糕。
GlusterFS-GITHUB 地址

HDFS
googlFS的java版实现,架构和上面的moosefs大致一样。非通用文件系统,只能通过API、Cli操作,专门针对大文件大数据设计,默认文件块128M(但不表示1M的文件浪费了127M硬盘空间)
HDFS架构上主要是NameNode(NN)和DataNode(DN), NN负责管理元数据(文件路径、大小、数据块id、存储位置,文件分配,DN管理等),DN负责文件存储。当一个DN节点失效,NN节点会根据元数据信息安排一些文件块在别的DN上增加备份。
HDFS适合做离线业务。
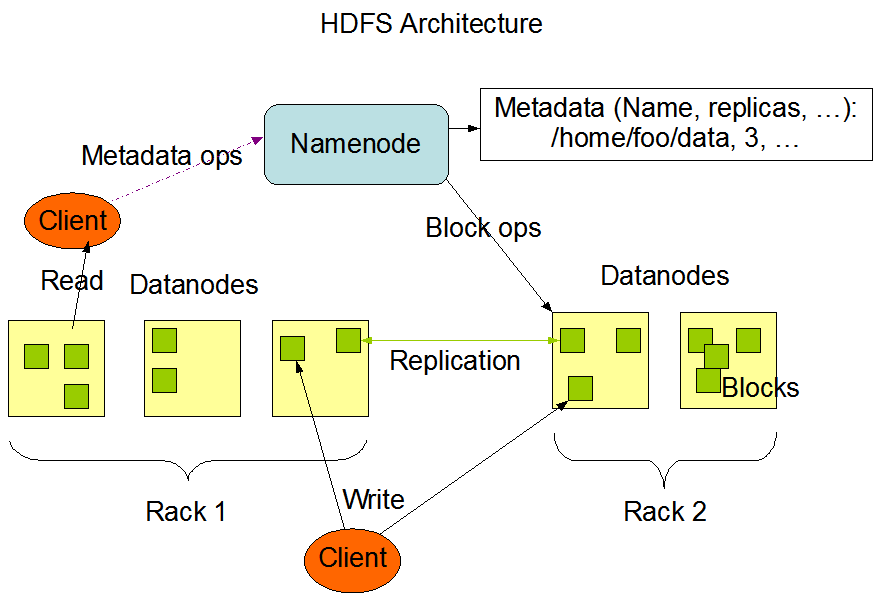
namenode有瓶颈(会加载所有元数据到内存,1亿个文件30G内存),跨机房 (跨机房引起节点之间带宽小,如hdfs设计时是大文件快速IO)
DCOS
开源数据中心操作系统,设计目标是让运维人员可以像操作电脑一样操作整个数据中心(执行分布式任务、管理硬件资源分配回收)
DCOS是一套系统框架,里面可以根据需要添加对应的服务,如HDFS、SPARK。有几十套大数据的框架选择。提供Web操作,部署很复杂的服务只需要几下简单的选择。 提供安全性更高的企业版。 具有漂亮的UI。
DCOS-GITHUB 地址

Spark
基于内存的的大数据并行处理框架,她不提供分布式文件系统,大多数情况依赖HDFS。MapReduce的替代方案。spark还提供类SQL的查询语言,实时(伪实时)数据流,MLlib常用机器学习算法库等工具。
Spark的任务编写语言只有Java、Python、 Scala。
Spark目前支持 HDFS, Amazon s3, 本地文件系统,http, ftp。(以及兼容hadoop规范的文件系统 https://wiki.apache.org/hadoop/HCFS)

分析
目前还不确定Spark像对BFS,mooseFS这种存储系统有没其他接入方式。如果可行的话,底层存储选用一个可以作线上业务的可能更加实用。 HDFS设计之初对小文件没有考虑 (其中一个解决方案是合并后上传,也有些插件)。
部署架构
SPark+HDFS(最简单部署,每次任务Spark的executor都会把节点上的资源全部利用)是很多团队的选择,也可能是Spark+Yarn/Mesos+HDFS(Yarn,Mesos都是资源调度).再复杂又会变成DCOS了。
Spark+HDFS 将会在内网运行, 数据来源会通过有公网IP的gateway程序写入。
Spark的worker节点和HDFS的dataNode节点重叠部署, 反而会提高spark读写效率。
大体还是master-slave结构 ,master有备机, slave >=3. 不算gateway保守5-7台服务器 。
代码例子
hdfs 读写
client, _ := hdfs.New("namenode:8020")
file, _ := client.Open("/tmp.txt")
buf := make([]byte, 59)
file.ReadAt(buf, 48847)
fmt.Println(string(buf))
spark 任务
text_file = sc.textFile("hdfs://...")
counts = text_file.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)
counts.saveAsTextFile("hdfs://...")
演示环境
WebUI
- HDFS http://10.2.35.13:50070/
- Spark http://10.2.35.13:8080/
可以在web上查看文件,任务、资源情况。如需提交任务需要cli操作。
cli操作
操作HDFS
上传文件到HDFS
ssh root@10.2.35.13
登录服务器 密码123456
cd /data/test
cp gameofthrones.txt ./input_files
测试hdfs, 这里选择一个文本文件, 放入当前目录内的 ./input_files (已通过windows 共享 \10.2.35.13\data\test ,需要登录则账号密码是root/123456 )
docker exec -it namenode /bin/bash
在name node上操作
hdfs dfs -mkdir /input
在hdfs上创建目录.执行后刷新 http://10.2.35.13:50070/explorer.html#/ 可以看刚添加的目录
hdfs dfs -put ./input_files/gameofthrones.txt /input
将文件添加到刚创建的目录
exit
操作Spark
通过进行word count案例来测试。
docker exec -it master /bin/bash
在spark master 上操作。
spark-shell --executor-memory 512M --total-executor-cores 2
启动 spark shell. --total-executor-cores 参数限次这次应用总的最多占用2个cpu资源。
sc.textFile("hdfs://namenode:8020/input/gameofthrones.txt").flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_ + _).sortBy(_._2,false).take(10).foreach(println)
输出整个txt中出现次数最多的十个单词 这是查看spark web ui, 会发现集群、任务运行信息。
ctrl+c
退出shell. 这是spark任务显示FINISHED, 群集的资源占用情况也归0.
exit
退出容器